Edge computing vs cloud is reshaping how organizations design modern technology architectures. This shift affects latency, bandwidth, data sovereignty, security, and total cost of ownership. The choice isn’t binary; it blends edge computing advantages with cloud computing vs edge computing capabilities. With a clear view of edge computing use cases and the broader cloud landscape, teams can design systems that are faster and more reliable. This primer outlines core architectures and practical balancing strategies for real-world deployments.
Beyond the buzz, the discussion shifts to local data processing and proximity-based computing. Instead of pushing every datapoint to a centralized data center, organizations harness on-site analytics, edge devices, and micro data centers for faster responses. In LSI terms, this translates to near-data processing, fog computing, and a resilient distributed edge that complements centralized cloud services. When teams talk about edge computing architecture, they mean the design of sensors, gateways, and local compute that feed a cloud-enabled governance layer. Ultimately, a hybrid approach—combining edge-first workflows with distributed cloud architecture—offers responsive performance alongside scalable analytics.
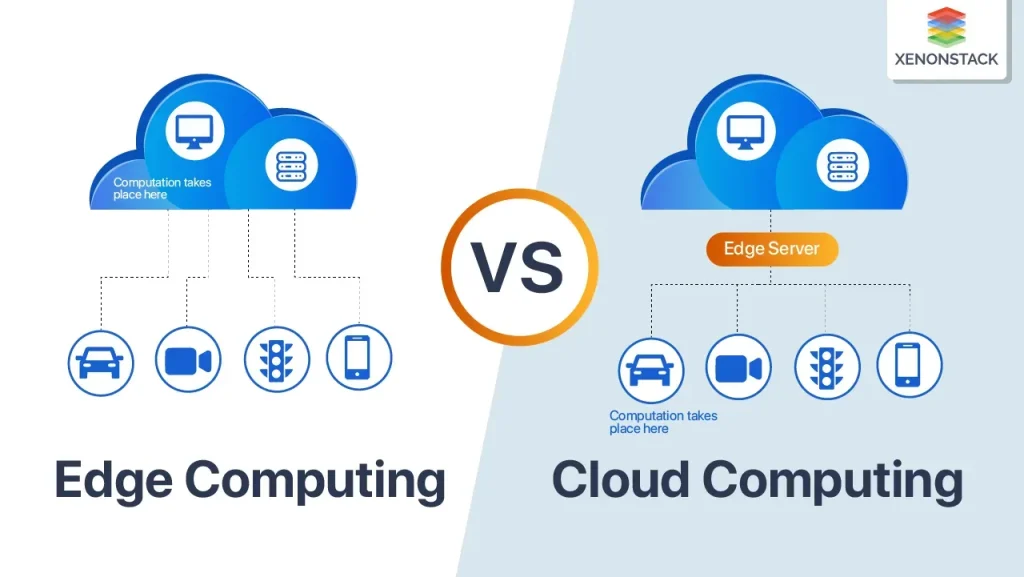
Edge computing vs cloud: Key differences in architecture, latency, and use cases
Edge computing architecture brings data processing to the source—on devices, gateways, or local micro data centers—closer to where data is generated. This setup reduces round-trip time, conserves bandwidth, and enhances reliability when connectivity to centralized data centers is intermittent. By design, it supports real-time analytics and local decision-making, leveraging edge computing architecture to enable immediate responses and offline operation in environments with limited connectivity. This approach aligns with the broader concept of a distributed cloud architecture, where compute and storage are positioned across multiple layers rather than centralized in a single location.
When evaluating Edge computing vs cloud, organizations weigh latency-sensitive tasks against data-heavy analytics. Edge computing advantages include lower latency for time-critical applications, local data filtering, and resilience in edge environments. Conversely, cloud computing vs edge computing excels in scalable analytics, model training, and centralized governance. In practice, many deployments use edge computing use cases—such as industrial automation, autonomous systems, and smart devices—for real-time inference, while reserving heavier analytics and long-term storage for the cloud.
Hybrid operation: how edge and cloud work together in a distributed cloud architecture
Understanding the hybrid model means recognizing how edge computing ecosystems connect with cloud capabilities. A layered edge computing architecture places sensors, edge gateways, and micro data centers at the edge, with a cloud layer handling larger-scale analytics, data lake storage, and centralized policy enforcement. This distributed cloud architecture enables a seamless blend of local responsiveness and cloud-scale processing, ensuring that edge tasks can feed summarized data to the cloud for deeper insights.
In practice, the decision to push computation to the edge or centralize it in the cloud hinges on workload characteristics, regulatory requirements, and total cost of ownership. The balance can be achieved by designing data routing rules, synchronization policies, and a governance layer that coordinates security, updates, and telemetry across both layers. This approach reflects the edge computing advantages while leveraging cloud computing vs edge computing for training, orchestration, and global data governance, creating a robust, scalable architecture.
Frequently Asked Questions
What are the edge computing advantages for latency-sensitive workloads, and how does this compare to cloud computing vs edge computing?
Edge computing advantages include lower latency, real-time processing at data sources, and reduced bandwidth. For many workloads, cloud computing vs edge computing centralizes heavy analytics and model training. A hybrid edge-to-cloud architecture assigns real-time tasks to the edge while using the cloud for storage, governance, and large-scale analytics, optimizing performance and total cost of ownership.
What are common edge computing use cases, and how does a distributed cloud architecture enable balancing edge and cloud roles?
Common edge computing use cases include industrial automation with real-time monitoring, predictive maintenance, smart cities, healthcare devices, and autonomous systems that require on-device inference. In a distributed cloud architecture, edge use cases are supported by edge gateways and local processing, while the cloud handles centralized analytics, data lakes, and global policy enforcement, enabling a practical balance between low latency at the edge and scalable cloud services.
| Aspect | Edge Computing | Cloud Computing | Notes / Hybrid Perspective |
|---|---|---|---|
| Definition | Processing at or near data source (devices, gateways, local data centers). | Centralized processing in scalable data centers/cloud regions. | Two ends of distributed architectures; hybrid approaches blend both. |
| Primary Architecture | Sensors/IoT → edge gateways → local data layer; real-time inference; local analytics. | Data lake/storage; centralized services; orchestration. | Edge handles real-time tasks; Cloud handles heavier analytics and governance. |
| Latency & Real-Time | Low latency and immediate responsiveness for time-sensitive tasks. | Great for large-scale analytics and orchestration; latency-sensitive tasks less optimal. | Hybrid balances immediacy and scale. |
| Data Management & Compliance | Local data processing supports data locality and compliance. | Long-term retention, cross-region analytics, centralized policy enforcement. | Edge + Cloud supports regulatory requirements and centralized governance. |
| Reliability & Connectivity | Operates with intermittent connectivity; local continuity. | Centralized synchronization and governance when connected. | Hybrid ensures continuity across distributed operations. |
| Cost & Scale | Reduces data movement and enables local decision-making; potential TCO savings for selected workloads. | Elastic scaling; reduces capex for peak demand. | Balance edge and cloud to optimize total cost of ownership. |
| Use Cases (Edge) | Industrial automation; predictive maintenance; smart cities; healthcare devices; autonomous systems. | Edge excels at real-time decisions; Cloud handles analytics and scale. | |
| Use Cases (Cloud) | Centralized analytics, model training, global governance, data lake, tooling. | ||
| Hybrid/Multi-Cloud Strategies | Hybrid architectures; edge gateways; local inference capabilities; MEC. | Central cloud data lake; data routing rules; orchestration. | Manage across layers with a common security model and governance. |
| Security, Observability | Device authentication; tamper resistance; secure boot; end-to-end encryption. | IAM, network segmentation, continuous monitoring; defense in depth. | Zero-trust and incident response across layers; unified telemetry. |
| Implementation Roadmap | Assess workloads; design layered architecture; pilot; scalable management; security. | Assess governance; define data routing; build scaling plan; implement cross-layer security. | Start small, measure, iterate; coordinate edge-cloud deployment across the organization. |
Summary
Edge computing vs cloud is a spectrum rather than a binary choice. For many organizations, the optimal architecture blends edge computing advantages with cloud computing capabilities to deliver fast, reliable, and compliant services. By understanding architectural differences, use cases, and strategic considerations, teams can design modern technology architectures that meet present needs while remaining adaptable for future requirements.